Doppel Named Official Partner of the New York Knicks
Partnership to Showcase Doppel to Knicks Widespread Audience Through In-Arena, Digital and Out-Of-Home Assets
How Doppel migrated to uv workspaces, Docker, and Cloud Run to build a foundation for scaling

At Doppel, we're a cybersecurity startup building a platform that protects brands from digital threats — phishing, counterfeiting, impersonation, and more. Like many growing startups, our Python backend evolved organically over the years. We ended up with more services than engineers, scattered dependency management, and deployments that got kicked off from developers' laptops.
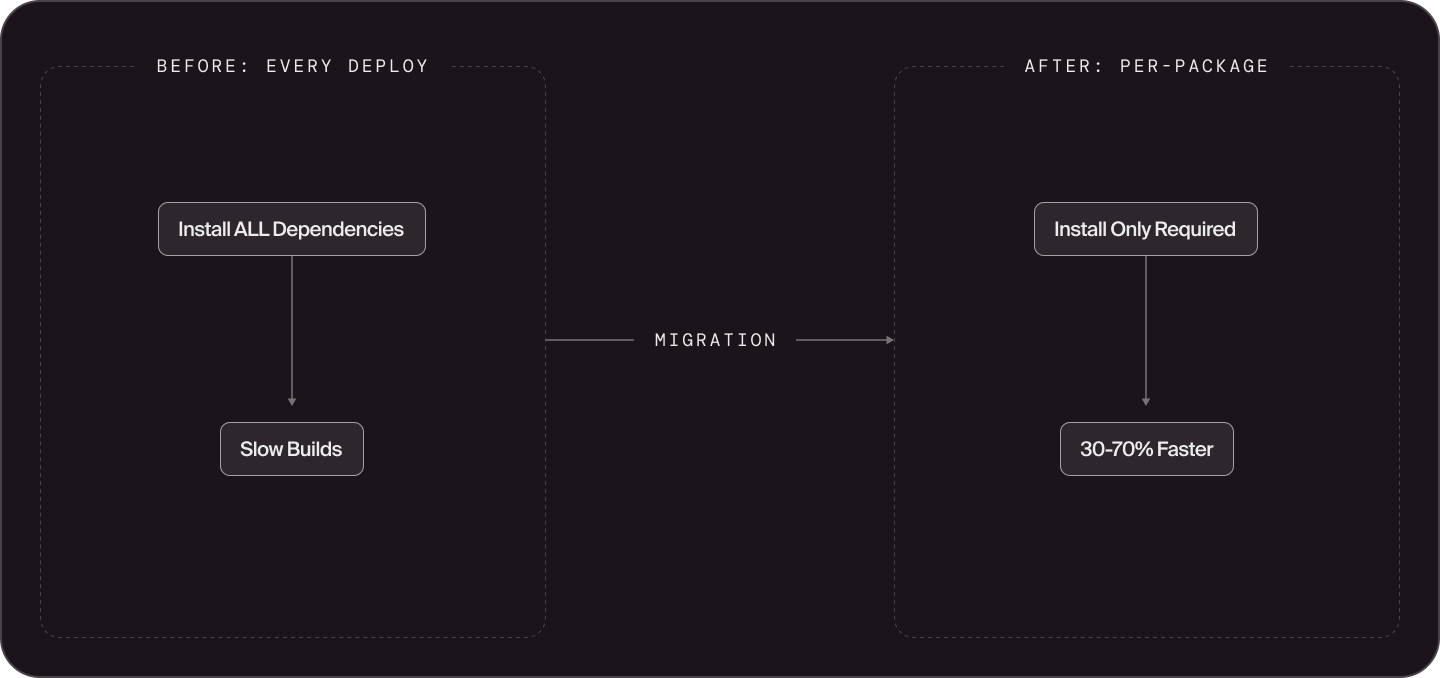
In the second half of 2025, we undertook a major infrastructure migration: moving our entire Python ecosystem to uv workspaces, Docker, and Google Cloud Run Services. The results exceeded our expectations. Build times dropped 30-70%, test times fell by roughly half, and we now have a foundation that can scale with our ambitious 2026 hiring plans.
This post shares what worked for us and isn’t meant to be prescriptive. Different teams have different constraints, and we're genuinely curious to hear how others are solving similar problems. If you're evaluating Python tooling for a growing codebase, we hope our experience provides useful data points.
Our backend had grown in the way many startups' backends do: quickly, pragmatically, and with whatever tools were at hand. The result was a codebase with several pain points.
Fragmented dependency management. Some services used requirements.txt files, others had adopted Poetry. Engineers managed Python versions with pyenv or conda, each with their own virtual environment setup. Shared code directories had their own scattered dependency files. Dependencies weren't defined intentionally — services often pulled in far more than they actually needed, and it was unclear which packages were truly required versus transitively inherited.
Service sprawl from architectural constraints. We had been using Google Cloud Functions (Gen 1) for deployment. Gen 1 Cloud Functions require a single entry point per function, which naturally led to creating many small, separate functions. What might have been a single service with multiple endpoints became a dozen individual deployments.
"Works on my machine" deployments. Code was packaged and deployed from developers' local machines. Deploy branches weren't tracked consistently. Different engineers had slightly different Python versions, dependency versions, and environment configurations.
No clear path to scale. We're planning to significantly grow our engineering team in 2026 (we're hiring!). Under the old setup, build and test times scaled poorly, growing significantly with more engineers and more code. Onboarding new engineers meant explaining a patchwork of different patterns across the codebase.
When evaluating solutions, we considered several options.
Poetry has been a popular choice for Python dependency management, but it lacks native workspace support for monorepos. Getting it to work across our scale would have required plugins and significant workarounds. We'd also experienced its dependency resolution being slow for complex dependency trees.
Pants and similar build systems are excellent tools for the right use case. While Pants still uses pip under the hood, it offers fine-grained caching, dependency inference, and powerful monorepo features. For our situation, uv workspaces fit our needs while letting us lean into modern Python tooling with strong industry momentum. We wanted to bet on tools that were consistently proving themselves as both fast and well-maintained.
uv won us over for several reasons:

We're a startup — new feature development matters. We couldn't disappear for months to rewrite monorepo infrastructure. However, we also knew that our current setup wouldn't scale with our growth plans, and the longer we waited, the more painful the migration would become.
Two things gave us confidence to start: First, we designed the migration in phases that could run in parallel with normal product work. Each phase delivered incremental benefits, so we weren't waiting months for a big-bang payoff. Second, our experiments with AI coding tools showed that, when provided a detailed migration prompt via a checked in Markdown file, they could handle much of the mechanical migration work reliably, which meant less engineering time away from key feature development.
Phase 1: uv-ify services. We started by converting individual services to use pyproject.toml with uv. Each service got its own package definition that declared only its actual dependencies instead of the superset of everything in the monorepo.
Before, several services in a team's directory might share a requirements.txt like this:
# requirements.txt - everything, whether needed or not
requests==2.31.0
flask==2.3.0
tensorflow==2.15.0
pandas==2.0.0
# ... hundreds more linesAfter, each package has a focused pyproject.toml:
[project]
name = "my-service"
version = "0.1.0"
dependencies = [
"fastapi",
"httpx",
# Internal workspace packages
"shared-auth",
"logging-utils",
]Phase 2: Reorganize shared libraries. Our shared code directories needed the most work. We refactored them into proper packages, each with its own pyproject.toml declaring explicit dependencies. This was the most labor-intensive part but paid the biggest dividends.
Phase 3: Containerize and consolidate. With a uniform build environment, we could standardize on Docker images and Cloud Run services. Cloud Run lets us deploy services with multiple endpoints, so we consolidated related Cloud Functions into fewer, more cohesive services.
The result: A unified uv workspace with a single lockfile, standardized patterns for both services and libraries, and CI/CD that builds and deploys from GitHub Actions rather than developer laptops.
We'd be remiss not to mention how AI coding tools significantly accelerated this migration. We used shared prompts with Claude Code and Cursor to guide the conversion of services and libraries to the new structure. Migration scripts using static analysis tooling are great, but we found that prompt-assisted migrations could cover edge cases specific to certain services or libraries that a script couldn't handle.
Many migrations were handled with minimal human intervention. LLM agents could read our migration guide written in Markdown, understand the existing code structure, and produce correct conversions. The consistent patterns we were migrating to made AI suggestions more reliable; there was one right way to structure a package, so the AI could learn it quickly. One of the best parts about this migration was that we were migrating to a standard that AI tools could take advantage of more easily, so it was trivial for AI tooling to make sure that a package was migrated correctly and that tests were passing.
We can't overstate how important it is to provide agentic tooling with a consistent feedback loop. When an LLM agent can run uv sync, make changes, run uv run pytest, and get reliable pass/fail signals, it can iterate autonomously. When that feedback loop is broken by environmental drift or inconsistent tooling, the agent's suggestions become unreliable and require constant human intervention.
This is another huge benefit of standardization in the modern coding era: it's not just easier for humans to understand the codebase — it's easier for AI tools too.
The numbers speak for themselves.
Build and deploy times: 30-70% reduction. Some of our services that previously took 10+ minutes to deploy now take less than 4 minutes. For context, we deployed a service 1,656 times in the last month. Previously, every service deployment installed the superset of all dependencies in the monorepo, including packages the service never even used. Now each service installs only what it declares. Service owners can analyze their dependency trees and optimize further if they want.
Test times: ~50% reduction on average, 90%+ for targeted PRs. Tests on PRs routinely took 10+ minutes, and now can complete in under 2 minutes for smaller PRs. Our CI now calculates which packages are affected by a PR and only runs tests for those packages and their dependents. A PR that touches a leaf-node service runs far fewer tests than one that modifies a core library. The feedback loop is dramatically tighter.
To do this, we built a small internal tool that uses uv tree --invert to find all packages that depend on a changed package:
📊 Analyzing 1 changed files
📦 Found 1 directly changed packages
- shared-auth
🔗 Found 4 total affected packages (including dependents)
- shared-auth (directly changed)
- api-gateway (shared-auth ← api-gateway)
- billing-service (shared-auth ← billing-service)
- web-app (shared-auth ← api-gateway ← web-app)
✅ Running tests for 4 packages instead of all packagesDependency hygiene with deptry. We integrated deptry into our workflow for per-package dependency checking. It catches unused dependencies (so we don't ship packages we don't need), ensures imports are properly declared (so we don't accidentally rely on transitive dependencies), and flags dependencies that should be dev-only. This kind of hygiene was nearly impossible before when everything was one giant dependency blob.
# In root pyproject.toml
[tool.deptry]
extend_exclude = ["test", "tests"]
[tool.deptry.per_rule_ignores]
DEP002 = ["uvicorn", "gunicorn"] # Runtime deps not imported directly
DEP003 = ["uvicorn", "gunicorn"] # Transitive deps we explicitly wantOne of the most valuable outcomes is environmental consistency. The same commands work everywhere:
This last point deserves emphasis. We've been investing heavily in AI-assisted development, using tools like Claude Code and Cursor with shared prompts to accelerate coding tasks both locally and in the cloud. (We'll have more to share about our AI background agents in a future blog post.) The consistent environment means AI tools get reliable test feedback. When writing new code or editing existing projects, they don't stumble over environment configuration differences or produce code that works in one context but fails in another.
Onboarding is now a single command. New engineers clone the repo, run our onboarding bootstrap.sh script that internally wraps uv sync and other setup commands, and they're ready to work on any part of the codebase. No more tracking down which Python version someone needs, which dependencies are missing, or which environment variables need to be set differently. This matters a lot when you're planning to grow your team — and we are.
No migration is without tradeoffs. Here's what we accepted:
Single lockfile means coordinated upgrades. With one uv.lock for the entire workspace, upgrading a dependency affects every package that uses it. Individual dependency upgrades need more careful auditing. In practice, this has been manageable. Our comprehensive test suite (running faster than before, thanks to targeted testing) catches issues quickly, and the consistency benefits outweigh the coordination costs.
Migration required dedicated effort. This wasn't a weekend project. It required sustained focus over several weeks, touching nearly every part of the backend codebase. We phased the work to minimize disruption, but it was still a significant investment.
New patterns to learn. Engineers had to learn the uv workspace model, the standardized package structure, and new commands. That being said, the learning curve was gentler than we expected. uv's commands are intuitive, and the consistency actually made onboarding easier overall.
We haven't fully reaped all the benefits yet, and that's exciting.
Package-based caching will let us skip rebuilding libraries that haven't changed. If a PR only touches one service, we shouldn't need to rebuild unrelated libraries for testing or deployment. Similarly, consistent tooling across all platforms will mean that we can even share a build cache between developer machines, background agents, and CI for faster builds across the board.
Package-based merge queues will become important as our team and commit frequency grow. When multiple PRs are ready to merge, we'll be able to test them in parallel based on which packages they affect, getting safe commits into main faster.
Continued service consolidation on Cloud Run. Now that services can have multiple endpoints, we can continue combining related functions into cohesive services, reducing operational overhead.
Cleaning up dependency trees. The migration surfaced some circular dependencies that had crept in over time. We've since cleaned those up and added a CI check that bans circular dependencies going forward. But we still have work to do: some of our simpler libraries have more transitive dependencies than they probably should, which means services that pull them in get heavier than necessary. uv tree gives us full visibility into these issues, so now we just need to chip away at them.
We're excited to keep investing in uv and modern, proven Python tooling. The foundation we've built can grow with us.
This post shared what worked for Doppel. Your constraints, scale, and priorities may be different. We'd genuinely love to hear what others are doing — whether you've adopted uv, went with Poetry, gone all-in on Pants, or found something else entirely. The Python ecosystem is better when we share what we learn.
If building reliable, modern Python infrastructure at a growing cybersecurity startup sounds interesting, we're hiring. Come help us protect brands from digital threats with a development environment that is built to scale.
Links:
A few specific uv commands have become essential to our daily workflow:
uv run < command > executes commands within the uv environment with the correct dependencies guaranteed. No more "I have a different version of black locally" issues:
uv run pytest # Tests with correct deps
uv run black . # Formatting
uv run ruff check . # Linting
uv run mypy # Type checkinguv tree visualizes the dependency graph. It's invaluable for understanding why a package is included and helping service owners optimize their dependency trees:
$ uv tree --package shared-auth --invert
shared-auth v0.1.0
├── api-gateway v0.1.0
│ └── web-app v0.1.0
├── billing-service v0.1.0
└── notification-service v0.1.0uv tool install <package> installs standalone CLI tools, isolated from project dependencies. We use this for internal tooling as part of engineer onboarding. One command installs our CLI utilities without polluting the project environment.
uv add <package> adds dependencies and automatically updates both pyproject.toml and uv.lock. Dependencies are correctly declared at the package level from the start.
uvx <tool> runs tools in ephemeral environments without installing them. Great for trying out tools or running one-off scripts.